 Model Architecture
Model Architecture
DLpMHCI is based on ensemble learning. Only peptide's architecture is discussed here because HLA's design is also consistent. The model was mainly divided into five modules:
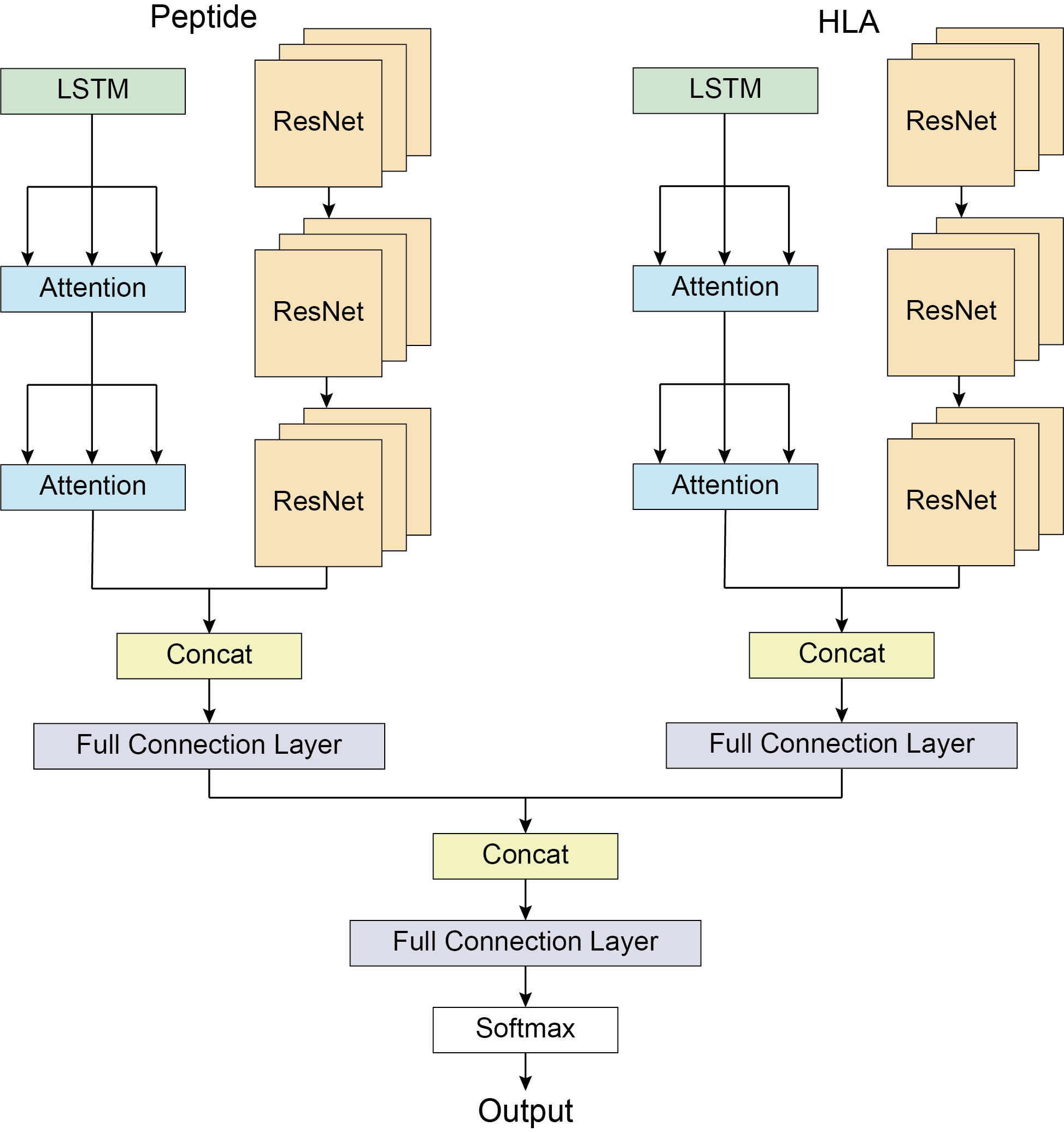
# Long-short-term memory (LSTM) module
The attention layer is created before the long-short-term memory layer. For feature extraction, the input sequence data is transferred through the long- and short-term memory layers. The size of the output matrix matches that of the input matrix.
# Attention module
The attention layer receives the output of the long short-term memory layer as input. The encoder block of the traditional model Transformer for natural language processing is used in the attention layer's architecture.
Here, we employ the scaling dot product technique, where d is the length of both the query and the key. Assume that the query and key are both made up of independent random variables with mean values of 0 and variances of 1. The variance is then d, and the mean value of the dot product of two vectors is 0. Use the scaled dot product attention scoring function to guarantee that the variance of the dot product is 1 regardless of the length of the vector:
To improve efficiency, small batch is considered. For example, we calculate attention based on n queries and m key value pairs, where the length of queries and keys is d and the length of values is v. The scale point product of query Q, key K and value V is:
The so-called self attention mechanism is that for a given sequence , the pooling layer of the self attention mechanism takes as a key, value, query to extract features from the sequence to get .
Position coding is applied to the peptide sequence input since the calculation of the attention mechanism does not take sequence timing information into account. The weight of the attention layer is initially set to 1, and a dropout rate of 5% is set to prevent overfitting. The attention module uses the dot product self attention computation approach. Following the completion of the attention computation, Layernorm is used to normalize all the dimensions of a single sample before they are propagated through the linear layer and the activation function. The model training is shielded from being impacted by the gradient's removal by residual connection.
# Residual module (ResNet module)
The residual network connects the classical convolutional neural network with the residual.
The model designs three residual modules. Each residual block contains two convolution layers. Residual blocks are connected with each other, and redundant information is removed through the maximum pooling layer. A 10% dropout is designed between residual blocks to prevent overfitting, and the ReLU() function is used as the activation function. The residual block is used to extract features in the peptide.
# Concat module
The Concat module connects and expands the output of the Attention and ResNet modules into a one-dimensional vector. Project the vector's length to twice its original size through a whole connection layer, then shrink it back down to its original size to extract the characteristics that the Attention and ResNet modules of the model have learned.
# Global concat module
The global concat module joins the one-dimensional vector outputs of the peptide and HLA, expands them into two-dimensional vector outputs of each, calculates the characteristics of the peptide binding to the HLA through a full connection layer, and outputs the softmax calculated from these features.
[1] Vaswani A, Shazeer N, Parmar N, et al. Attention Is All You Need[J]. arXiv, 2017.